
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- self-attention
- 트랜스포머 모델
- AI Math
- 네이버 부스트캠프
- Transformer 디코더
- Auto-Encoding Variational Bayes
- 네이버 ai 부스트캠프
- 어텐션
- 트랜스포머 행렬
- 네이버 부스트캠프 AI Tech 6기
- Transformer model
- 포지셔널 인코딩
- 부스트캠프
- 네이버 부스트캠프 KDT 전형
- VAE 설명
- transformer
- 셀프 어텐션
- seq2seq
- 네이버 부스트캠프 AI Tech
- Transformer 모델
- 네이버 부스트캠프 코딩테스트 후기
- Positional Encoding
- VAE 논문 리뷰 #
- 주간학습정리
- boostcamp
- 트랜스포머
- pytorch
- VAE
- Transformer Decoder
- 어텐션 행렬
- Today
- Total
DH. AI
[딥러닝] 트랜스포머(Transformer) 하이퍼파라미터, 인코더와 디코더, 포지셔널 인코딩 본문
"Attention is all you need"에서 나온 모델로 기존의 seq2seq의 구조인 인코더-디코더를 따르면서도, 논문의 이름처럼 어텐션(Attention)만으로 구현한 모델입니다. 이 모델은 RNN을 사용하지 않고, 인코더-디코더 구조를 설계하였음에도 번역 성능에서도 RNN보다 우수한 성능을 보여주었습니다.
1. 기존의 seq2seq 모델의 한계
기존의 seq2seq 모델은 인코더-디코더 구조로 구성되어져 있는데, 인코더는 입력 시퀀스를 하나의 벡터 표현으로 압축하고, 디코더는 이 벡터 표현을 통해서 출력 시퀀스를 만들어냈습니다. 하지만, 인코더 부분에서 입력 시퀀스를 하나의 벡터로 압축하는 과정에서 입력 시퀀스의 정보가 손실되는 문제가 있습니다. 그래서 이를 보정하기 위한 목적으로 어텐션이 사용되었는데, 어텐션 만으로 인코더와 디코더를 만들어 버리는 것이 Transformer 모델 입니다.
2. 트랜스포머(Transformer)의 주요 하이퍼파라미터
하이퍼파라미터의 의미는 뒤에서 설명하고 여기서는 이러한 하이퍼파라미터가 존재한다 정도로만 이해합니다.
아래에서 정의하는 수치는 트랜스포머를 제안한 논문에서 사용한 수치로 하이퍼파라미터는 사용자가 모델 설계시 임의로 변경할 수 있는 값들입니다.
d_model = 512 : 트랜스포머의 인코더와 디코더에서의 정해진 입력과 출력의 크기를 의미합니다. 임베딩 벡터의 차원 또한 d_model이며, 각 인코더와 디코더가 다음 층의 인코더와 디코더로 값을 보낼 때에도 이 차원을 유지합니다.
num_layers= 6 : 트랜스포머에서 하나의 인코더와 디코더를 층으로 생각하였을 때, 모델에서 층의 개수.
num_heads = 8 : 트랜스포머에서는 어텐션을 사용할 때, 한 번 하는 것 보다 여러 개로 분할해서 병렬로 어텐션을 수행하고 결과값을 다시 하나로 합치는 방식을 택했습니다. 이때 병렬의 개수.
d_ff = 2048 : 트랜스포머 내부에는 피드 포워드 신경망이 존재하며 해당 신경망의 은닉층의 크기를 의미합니다. 피드 포워드 신경망의 입력층과 출력층의 크기는 d_model입니다.
3. 트랜스포머(Transformer)

트랜스포머는 RNN을 사용하지 않지만, 인코더에서 입력 시퀀스를 입력받고, 디코더에서 출력 시퀀스를 출력하는 인코더-디코더 구조를 유지합니다. seq2seq 구조에서는 인코더와 디코더에서 각각 하나의 RNN이 t개의 시점(time step)을 가지는 구조였다면, 이번에는 인코더와 디코더라는 단위가 N개로 구성되는 구조입니다.
위의 그림은 인코더로부터 정보를 전달받아 디코더가 출력 결과를 만들어내는 트랜스포머 구조를 보여줍니다. 디코더는 마치 기존의 seq2seq 구조처럼 시작 심볼 <sos>를 입력으로 받아 종료 심볼 <eos>가 나올 때까지 연산을 진행합니다.
디코더와 인코더의 구조를 이해하기 전에, 트랜스포머의 입력에 대해서 이해해보겠습니다. 트랜스포머의 인코더와 디코더는 단순히 각 단어의 임베딩 벡터들을 입력받는 것이 아니라 임베딩 벡터에서 조정된 값을 입력받습니다.
4. 포지셔널 인코딩(Positional Encoding)
트랜스포머는 단어 입력을 순차적으로 받는 방식이 아니므로 단어의 위치 정보를 다른 방식으로 알려줄 필요가 있습니다. 트랜스포머는 단어의 위치 정보를 얻기 위해서 각 단어의 임베딩 벡터에 위치 정보들을 더하여 모델의 입력으로 사용하는데, 이를 포지셔널 인코딩(positional encoding)이라고 합니다.
트랜스포머는 RNN과 달리, 문장의 단어를 하나씩 받는것이 아니라 한번에 받습니다. 따라서, 포지셔널 인코딩을 추가해주어서 위치정보를 모델에 넣어 주어야합니다.
포지셔널 인코딩 값들은 어떤 값이기에 위치 정보를 반영해줄 수 있는 것일까요? 트랜스포머는 위치 정보를 가진 값을 만들기 위해서 아래의 두 개의 함수를 사용합니다.
위의 함수를 이해하기 위해서는, 위에서 본 임베딩 벡터와 포지셔널 인코딩의 덧셈은 사실, 임베딩 벡터가 모여 만들어진 문장 행렬과 포지셔널 인코딩 행렬의 덧셈 연산을 통해 이루어진다는 점을 이해해야 합니다.
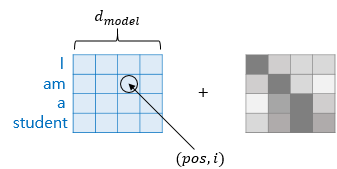
pos는 입력 문장에서의 임베딩 벡터의 위치를 나타내며, i는 임베딩 벡터 내의 차원의 인덱스를 의미합니다. 위 그림의 포이터에서 pos와 i의 시작이 0이라고 가정해봅시다. pos값은 두번째 단어이므로 1, i값은 3번째 인덱스 이므로 2입니다.
위의 수식에서 짝수(pos, 2i)일 때는 사인 함수를, 홀수(pos, 2i+1)일 때는 코사인 함수를 사용하고 있음을 주목합시다.
(d_model의 값은 4가 아니라, 실제로는 512입니다.)
위와 같은 포지셔널 인코딩 방법을 사용하면 순서 정보가 보존되는데, 예를 들어 각 임베딩 벡터에 포지셔널 인코딩의 값을 더하면 같은 단어라고 하더라도 문장 내의 위치에 따라서 트랜스포머의 입력으로 들어가는 임베딩 벡터 값이 달라집니다. 즉, 같은 단어라도 트랜스포머 모델에 순서 정보가 고려된 임베딩 벡터를 입력 해줄 수 있는 것입니다.
- 원본 논문에서는 하나의 문장에 포함되어 있는 각각의 단어들에 대한 상대적인 위치 정보를 모델에서 알려주기 위해서 주기함수인 sin, cos 함수를 사용했습니다. 10000이나 sin, cos은, 다른 숫자나 다른 주기함수로 변경 될 수도있습니다.
- 결론적으로, 모델이 각각의 입력 문장에 포함되어 있는 각 단어들의 상대적인 위치 정보를 알 수 있도록 이러한 주기성을 학습할 수 있도록 해주어야 합니다.
-딥 러닝을 이용한 자연어 처리 입문을 참고하였습니다. -
'[딥러닝] > [Transformer]' 카테고리의 다른 글
| [딥러닝] 트랜스포머(Transformer) Position-wise FFNN, Residual connection & Layer Normalization, 디코더 (0) | 2022.08.07 |
|---|---|
| [딥러닝] 트랜스포머(Transformer) 어텐션, 인코더, 셀프 어텐션 (0) | 2022.08.07 |
| [딥러닝] 어텐션 메커니즘 (Attention Mechanism) (0) | 2022.08.06 |


